얼마전부터 antirez twitter에서 radix tree 관련 트윗이 올라왔습니다. 얼마 지나지 않아 antirez가 radix tree를 구현한 rax 프로젝트를 공개하고 redis의 cluster hash_slot의 저장구조를 radix tree로 수정 되는것을 보았습니다.
그동안 antirez의 코드 읽으면서 배우는 게 많았고, 자료구조에 관심이 많아서 살펴보기 시작했습니다. radix tree를 왜 구현 했는지, 어떻게 구현쟀는지 알아보고 radix tree를 redis에 어떻게 적용하였는지도 알아보겠습니다.
antirez는 redis의 hash-slot -> key 구조에서 중복으로 인한 메모리 사용을 줄이기 위해 radix tree 를 만들었다고 합니다. 이 포스트에선 rax를 적용시킨 redis cluster로 이야기를 진행 하겠습니다.
“현재는 hash-slot -> key에만 사용되지만 추후에는 다양한 곳에 사용 예정”이라는 트윗
redis cluster?
redis에는 cluster 기능이 있습니다.
6대 이상의 redis 노드를 cluster 구성하면(최소 leader 3대, follower 3대 구성해야 cluster 가능) 16384개의 hash_slot이 노드 갯수에 맞게 분배가 됩니다. 즉 3대의 leader로 cluster 구성하면 각각의 leader는 0 ~ 5460, 5461 ~ 10922, 10923 ~ 16383 hash_slot을 나눠 가집니다.
cluster 구성 후 client가 데이터 저장/삭제/조회 명령어를 redis server에 전송할 때 마다 key의 hash값을 구하고 어떤 leader hash_slot에 포함되는지 찾습니다.
# example
127.0.0.1:7000> set hello world
# hash_slot = crc16("hello") & 0x3FFF
계산된 값이 현재 접속한 leader의 hash_slot 범위에 있다면 그대로 실행 되지만 다른 leader의 hash_slot 이라면 에러를 발생하고 다른 leader로 이동하라고 힌트를 줍니다.
cluster 구성 후에 노드를 추가 하거나 제거 할 경우 각 leader의 hash_slot을 재분배 하고, hash_slot에 맞게 key도 재분배 되어야 합니다. 단순하게 생각하면 leader의 hash_slot 재분배한 후 모든 key를 재계산하고 hash_slot에 맞는 leader에 할당 하는 겁니다.
[현재까지 저장된 keys].forEach(v => {
hash_slot = crc16(v) & 0x3FFF
// leader에 할당된 hash_slot에 맞게 분배
})
하지만 antirez는 redis Sorted set 데이터 타입의 구현체인 skiplist 을 이용하여 문제를 풀었습니다. skiplist는 member와 score를 저장하고, score를 기준으로 정렬합니다. skiplist의 member에는 key를 저장하고 score에는 key의 hash_slot을 저장합니다.(변수명 slots_to_keys)
slots_to_keys 정보는 cluster 구성된 모든 노드가 저장합니다. 이후 재분배가 필요해지면 16384개 hash_slot을 leader 갯수에 맞게 재분배 하고 slots_to_keys에 저장된 “key:hash_slot” 정보를 가지고 해당 hash_slot의 key를 조회 및 재분배 합니다. 즉 slots_to_keys에 이용하여 재분배시 발생하는 계산을 없앤것입니다.
잘 했구만 뭐가 문제냐?
redis에 key가 추가/삭제 될때마다 slots_to_keys에 데이터가 저장되고 지워집니다. redis에 저장되는 key 갯수가 증가 할수록 slots_to_keys의 크기도 커짐을 의미 합니다.(※ 메모리 사용량)
또한 leader 갯수에 맞게 16384개 hash_slot을 leader에 재분배하고, 각 hash_slot에 맞는 key를 찾고 할당 합니다. 예를들어 slots_to_keys에서 score 0인(hash_slot 0을 의미) member를 조회해서 0번 hash_slot에 할당, score 1인 member를 조회해서 1번 hash_slot에 할당 하는 방식으로 0 ~ 16383 hash_slot을 진행합니다.
앞에서 말한 hash_slot에 속한 key를 조회 하는 GETKEYSINSLOT 명령어가 있는데 여기에 이슈가 있습니다.
cluster GETKEYSINSLOT slot count
# slot: hash_slot 번호
# count: 특정 hash_slot에서 조회할 key 갯수
# example
127.0.0.1:7000> cluster GETKEYSINSLOT 0 3 # 0번 hash_slot의 key를 3개 조회한다.
"47344|273766|70329104160040|key_39015"
"47344|273766|70329104160040|key_89793"
"47344|273766|70329104160040|key_92937"
사용자가 특정 hash_slot에 몇개의 key가 저장 되었는지 모르기때문에 count에 Integer.MAX 를 대입하는데, redis는 hash_slot에 실제로 저장된 key 갯수와는 상관없이 client가 전달한 count만큼의 메모리를 할당합니다.
} else if (!strcasecmp(c->argv[1]->ptr,"getkeysinslot") && c->argc == 4) {
/* cluster GETKEYSINSLOT <slot> <count> */
long long maxkeys, slot;
unsigned int numkeys, j;
robj **keys;
// ... 명령어의 4번째 인자를 maxkeys에 할당, 즉 사용자가 입력한 count
if (getLongLongFromObjectOrReply(c,c->argv[3],&maxkeys,NULL)
!= C_OK)
return;
// ...
keys = zmalloc(sizeof(robj*)*maxkeys);
numkeys = getKeysInSlot(slot, keys, maxkeys);
addReplyMultiBulkLen(c,numkeys);
for (j = 0; j < numkeys; j++) addReplyBulk(c,keys[j]);
zfree(keys);
zmalloc maxkeys
cluster GETKEYSINSLOT unnecessarily allocates memory
그래서 메모리도 적게 차지하면서(압축 가능) key와 key의 hashslot을 효율적으로 저장 및 조회가 가능한 자료구조가 필요했고 antirez는 radix tree를 선택합니다.
※ 뜬금 없는데 2012년, redis 자료형에 Trie를 추가한 P/R이 생각났습니다.
radix tree 구현한 rax 알아보기
시작하기전 radix tree (Wikipedia) 위키 페이지의 그림을 보고 감을 잡은 후에 아래를 보시면 잘 읽힙니다.
자! 이제부터 rax의 주석과 코드를 보면서 어떻게 구현됐는지 알아보겠습니다.
Node
rax의 노드 구성은 다음과 같습니다.
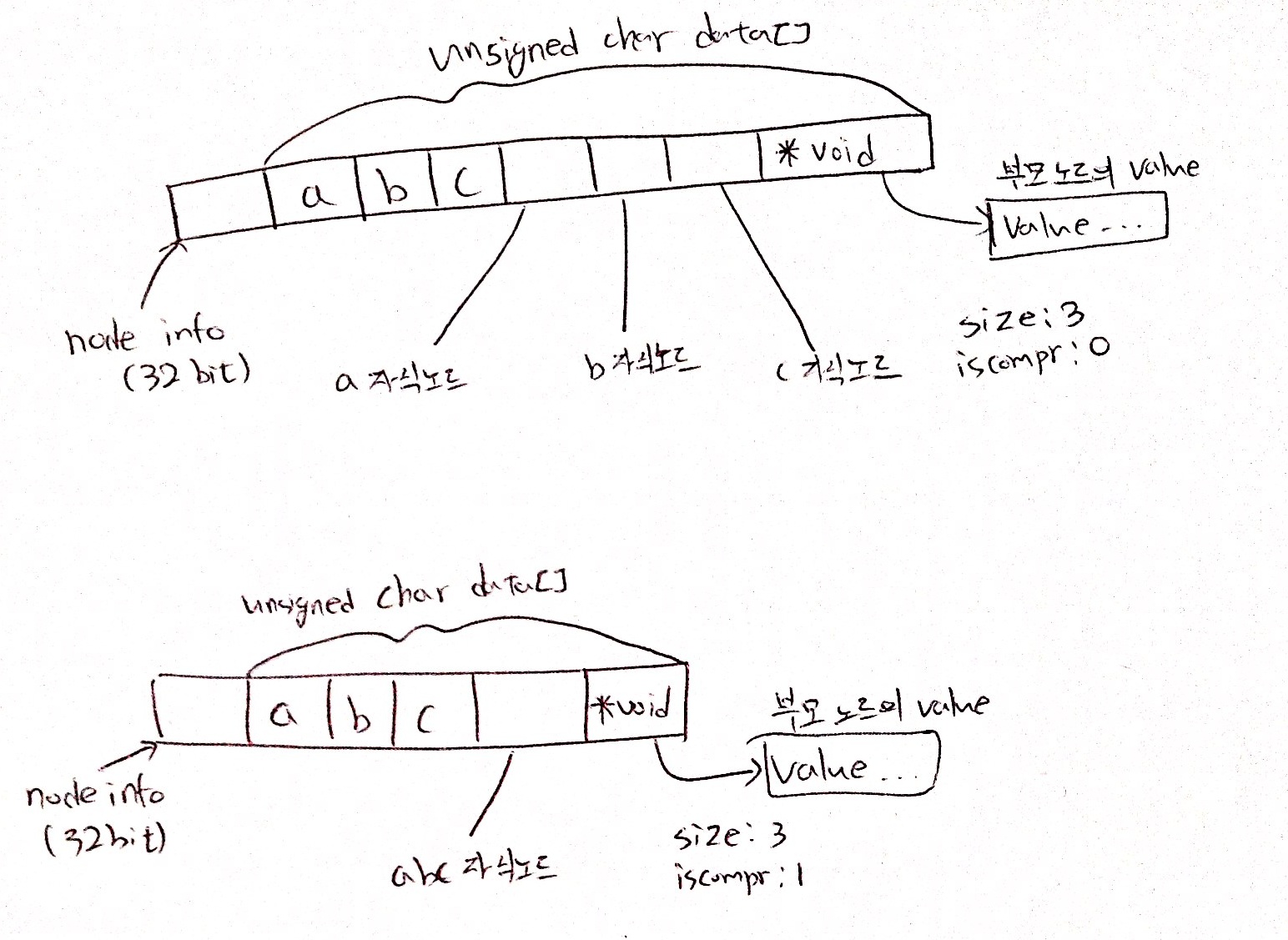
typedef struct raxNode {
uint32_t iskey:1; /* Does this node contain a key? */
uint32_t isnull:1; /* Associated value is NULL (don't store it). */
uint32_t iscompr:1; /* Node is compressed. */
uint32_t size:29; /* Number of children, or compressed string len. */
unsigned char data[];
} raxNode;
노드의 정보를 담고있는 32 bit(iskey, isnull, iscompr, size)와 key/value 그리고 자식 노드의 포인터를 저장하는 unsigned char data[]가 있습니다. 특이한 점은 key/value를 동일한 노드에 저장 하지 않고 key가 저장된 노드의 자식 노드에 value를 저장합니다.
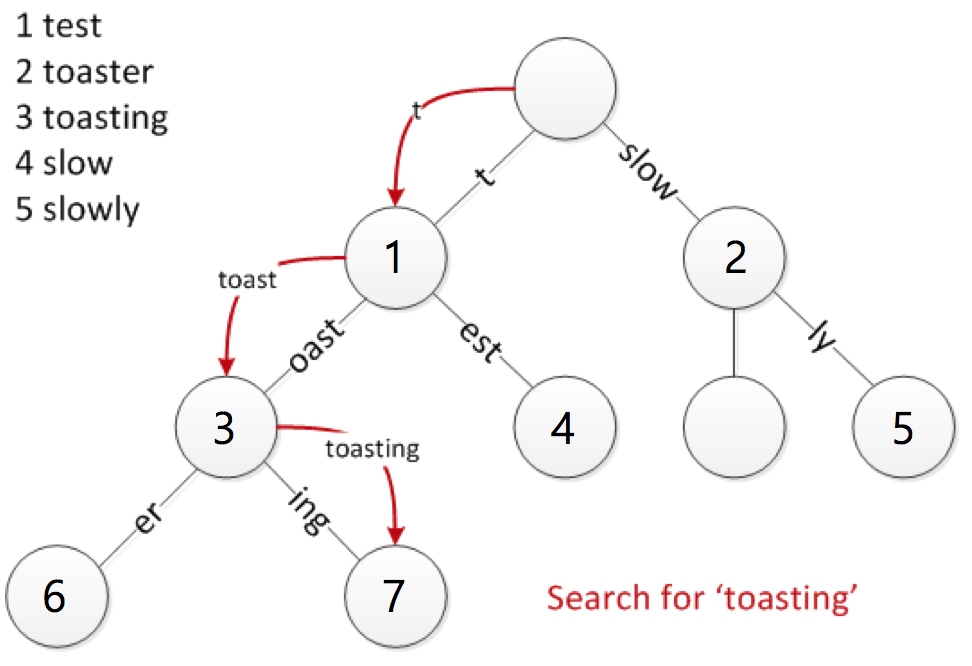 ※ 사진 출처
※ 사진 출처
위 그림을 예로 32 bit 정보가 어떤걸 의미하는지 알아보겠습니다.
iskey는 노드가 key의 종착역(iskey:1)인지 중간역(iskey:0)인지 나타내는 flag입니다. 1, 3 노드는 iskey:0 이고 2, 4, 5, 6, 7 노드는 iskey:1이 됩니다.
isnull은 value의 null 여부를 표시합니다. unsigned char data[]에 key/value 그리고 자식 노드의 포인터를 저장하므로 value를 찾으려면 계산이 들어갑니다. 불필요한 연산을 줄이기 위해 만든 필드 같습니다.
Trie는 각 노드에 한글자씩 표현 하지만 Radix는 압축을 통해 한 노드에 여러 글자 표현이 가능합니다. 이를 나태내는 플래그 iscompr 입니다. 노드가 압축된 노드(iscompr:1)인지 아닌지(iscompr:0)를 나타냅니다.
size는 iscompr 값에 따라 의미가 다릅니다. iscompr이 1이면 저장된 key의 길이를 의미하고 iscompr이 0이면 자식노드의 갯수(저장된 key의 갯수)를 의미합니다.
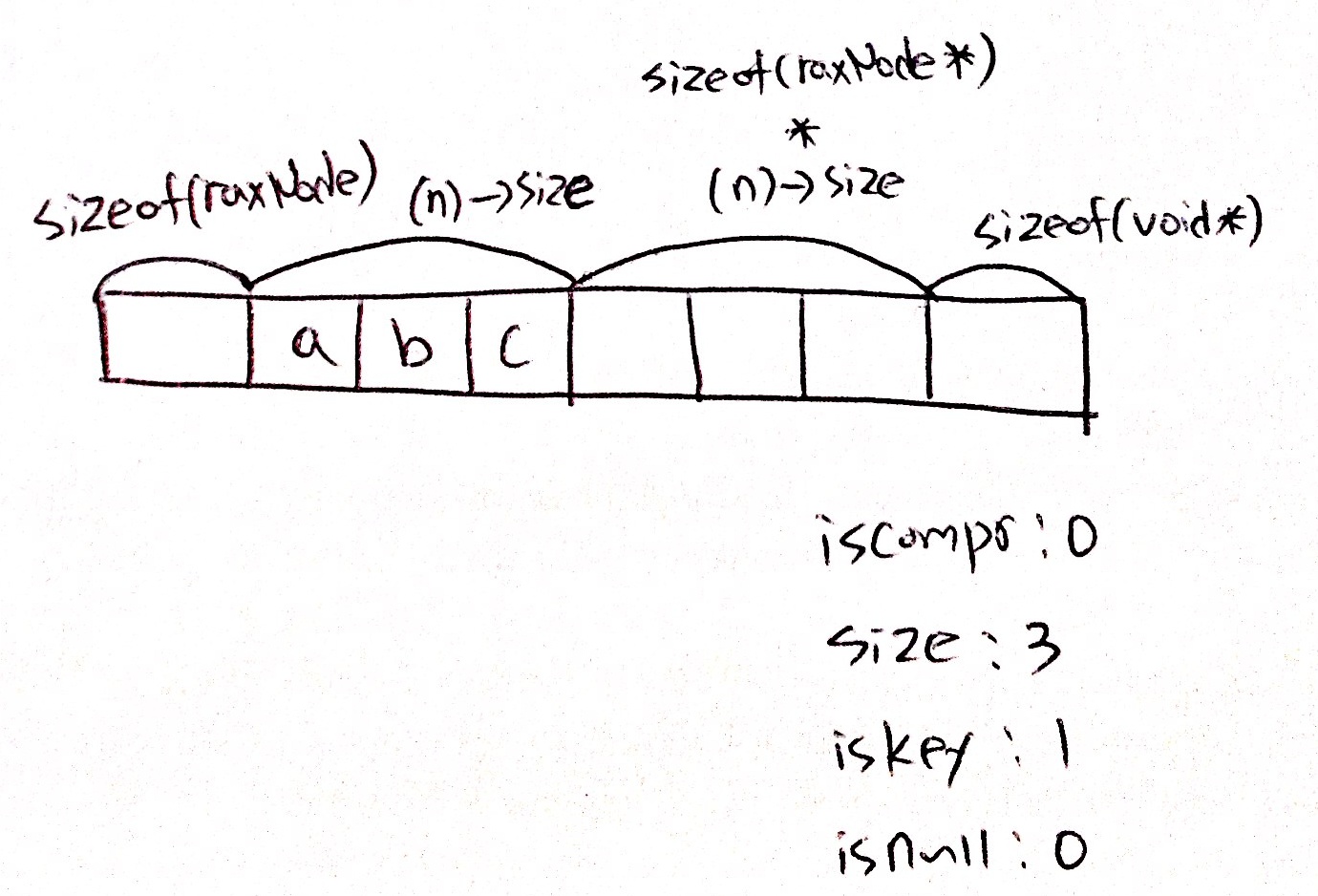
위 4개 정보를 이용해서 한 노드의 크기를 구하는 코드는 아래와 같습니다.
#define raxNodeCurrentLength(n) ( \
sizeof(raxNode)+(n)->size+ \
((n)->iscompr ? sizeof(raxNode*) : sizeof(raxNode*)*(n)->size)+ \
(((n)->iskey && !(n)->isnull)*sizeof(void*)) \
)
 ※ 노드에 value 주소를 저장하거나, 마지막 자식 노드 포인터를 알고 싶을때 사용합니다.
※ 노드에 value 주소를 저장하거나, 마지막 자식 노드 포인터를 알고 싶을때 사용합니다.
Find
raxLowWalk 함수를 이용해 key가 존재 하는지 판단합니다.
size_t raxLowWalk(rax *rax, unsigned char *s, size_t len, raxNode **stopnode, raxNode ***plink, int *splitpos, raxStack *ts)
rax에 “ANNIBALE” -> “SCO” -> [] 로 저장 되어있을때 어떤 값을 리턴하는지 알아보겠습니다.
*s 가 “ANNIBALESCO”이고 len이 11 인 경우
# splitpos: 0, return value: 11
"ANNIBALE" -> "SCO" -> []
^
|
*stopnode
*s가 “ANNIBALETCO”이고 len이 11인 경우
# splitpos: 0, return value: 9
"ANNIBALE" -> "SCO" -> []
^
|
*stopnode
*s의 길이 len과 return value가 같다면 rax에 key가 존재하는 것입니다. *s의 길이 len과 return value가 다른 경우 어디까지 매칭됐는지 보여주는 return value와 어떤 노드에 어디까지 일치했는지 표현하는 *stopnode, splitpos를 통해 추가 정보를 얻을수 있습니다.
Insert
- raxLowWalk 함수를 이용해서 저장할 위치를 찾습니다. (*stopnode, splitpos, return value)
- 1번에서 구해진 데이터를 이용해서 새로운 노드 생성 및 링크를 연결합니다.
rax에 “ANNIBALE” -> “SCO” -> [] 상태에서 “ANNIENTARE”를 저장하는 과정입니다.
1. raxLowWalk 함수를 이용하여 저장할 위치 탐색
splitpos: 4, return value: 4
"ANNIBALE" -> "SCO" -> []
^
|
*stopnode
2. *stopnode, splitpos 데이터를 이용하여 노드 분리
"ANNI" -> "B" -> "ALE" -> []
3. iscompr: 0인 노드 "B"를 기준으로 새로운 key 저장
("B"와 "E"는 같은 노드)
|B| -> "ALE" -> []
"ANNI" -> |-|
|E| -> "NTARE" -> []
Remove
- raxLowWalk 함수를 이용해서 저장할 위치를 찾습니다. (*stopnode, splitpos, return value)
- 1번에서 구해진 데이터를 이용해서 노드 제거 및 compress가 가능다면
2가지 경우가 있습니다.
마지막 노드만 iskey: 1이고, 연속으로 iscompr:1인 노드가 된 경우
마지막 노드만 iskey: 1이고, iscompr:1 -> iscomplr:0 -> iscomplr:1 노드 구조가 된 경우입니다.
첫번째 경우를 알아 보겠습니다. rax에 “FOO” -> “BAR” -> [] 상태에서 “FOO”를 지우는 과정입니다.
1. raxLowWalk 함수를 이용하여 저장할 위치 탐색
splitpos: 3, return value: 3
"FOO" -> "BAR" -> []
^
|
*stopnode
2. 해당 key 삭제, 여기서는 자식노드가 있으므로 노드 삭제는 하지 않고 노드의 iskey: 0으로 세팅
"FOO" -> "BAR" -> []
3. compress가 가능한 경우 진행
"FOOBAR" -> []
두번째 경우를 알아 보겠습니다.
0. "FOOBAR"와 "FOOTER"가 저장된 상황입니다. FOOTER를 지우는 경우입니다.
|B| -> "AR" -> []
"FOO" -> |-|
|T| -> "ER" -> []
1. raxLowWalk 함수를 이용하여 저장할 위치 탐색
splitpos: 0, return value: 6
|B| -> "AR" -> []
"FOO" -> |-|
|T| -> "ER" -> []
^
|
*stopnode
2. 해당 key 삭제
"FOO" -> "B" -> "AR" -> []
3. compress가 가능한 경우 진행
"FOOBAR" -> []
cluster 정보는 어떻게 저장되나?
기존 skiplist 자료구조를 이용했던게 어떻게 변경 되었는지 알아보겠습니다.
server.cluster->slots_keys_count[hashslot] += add ? 1 : -1;
if (keylen+2 > 64) indexed = zmalloc(keylen+2);
indexed[0] = (hashslot >> 8) & 0xff;
indexed[1] = hashslot & 0xff;
memcpy(indexed+2,key->ptr,keylen);
if (add) {
raxInsert(server.cluster->slots_to_keys,indexed,keylen+2,NULL,NULL);
} else {
raxRemove(server.cluster->slots_to_keys,indexed,keylen+2,NULL);
}
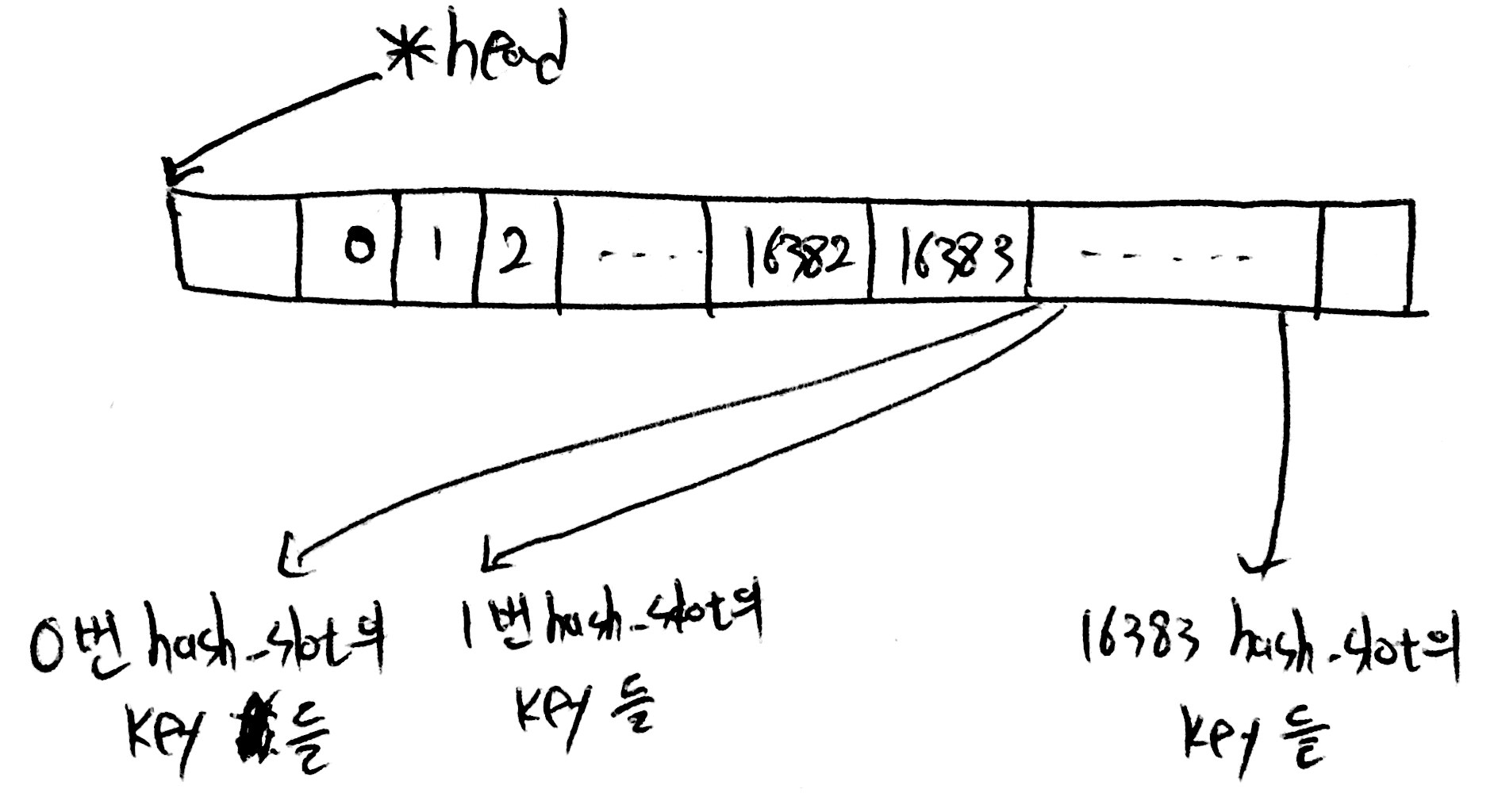
먼저 slots_keys_count 변수를 이용하여 각 hash_slot의 key 갯수를 저장합니다.
그리고 key는 hash_slot(2 byte) + key, value는 NULL로 rax에 저장하여 특정 hash_slot에 속한 key 조회를 쉽게 만들었습니다.
마치며
rax 구현과 rax가 어떻게 redis에 적용됐는지 보면서 오랜만에 재밌게 코드를 읽은것 같습니다. 개인적으로 데이터 관련 유용한 무언가를 만드는게 목표인데, 이런 좋은 코드들을 하나 둘씩 제것으로 만드는것도 과정이라 생각하며 진행했습니다.
앞으로 rax가 redis에서 어떻게 쓰일지 흥미롭고, Redis를 Saas 형태로 제공하는 업체들이 언제 적용할지도 궁금합니다.
긴 글 읽어주셔서 감사합니다.
cluster, rax 관련 antirez twitter
Redis cluster Insertion cluster Issue
same amount data hash table vs radix tree
hashset + ziplist -> radix tree + listpack 1/5
replace Hashset with Radix tree
raxNode에서 사용한 flexible member
rax 를 이용한 Redis Streams(2017.12.17일 업데이트)
